Text-to-Speech (TTS) là gì?
Trí tuệ nhân tạo (AI) đang là xu hướng phát triển mạnh mẽ trên toàn cầu, ứng dụng rộng rãi trong mọi lĩnh vực từ giáo dục, y tế, đến sản xuất và kinh doanh. Một trong những ứng dụng nổi bật và ngày càng phổ biến của AI chính là công nghệ Text-to-Speech (TTS).
Text-to-Speech (TTS) là công nghệ chuyển đổi văn bản thành giọng nói, cho phép máy tính hay các thiết bị điện tử đọc lên nội dung dạng chữ viết một cách rõ ràng và tự nhiên, tương tự như giọng nói con người.
🚀 Ứng dụng phổ biến của TTS
- Trợ lý ảo: Google Assistant, Siri, Alexa…
- Audiobook: Chuyển đổi sách, báo, tài liệu từ dạng chữ sang audio.
- Ứng dụng giáo dục: Hỗ trợ học ngoại ngữ, phát âm chuẩn.
- Ứng dụng trợ năng: Giúp người khiếm thị tiếp cận thông tin.
- Hệ thống trả lời tự động: Tổng đài chăm sóc khách hàng tự động.
📌 Nguyên lý hoạt động
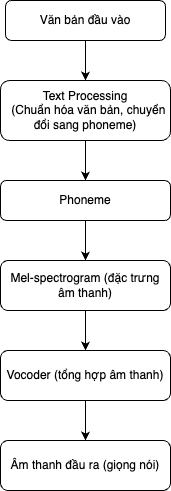
Hệ thống TTS hoạt động theo hai bước chính như sau:
Text Processing (Xử lý văn bản)
Đây là bước đầu tiên và rất quan trọng của hệ thống TTS, bao gồm:
Chuẩn hóa văn bản đầu vào:
- Loại bỏ các ký tự đặc biệt, dấu câu dư thừa.
- Chuyển đổi các từ viết tắt thành dạng đầy đủ (VD: "TP.HCM" → "Thành phố Hồ Chí Minh").
- Xử lý số, ngày tháng sang dạng văn bản dễ phát âm (VD: "30/4" → "ba mươi tháng tư").
Ví dụ minh họa:
Văn bản gốc: "Hôm nay, 30/4, tôi đến TP.HCM."
Sau chuẩn hóa: "Hôm nay, ba mươi tháng tư, tôi đến Thành phố Hồ Chí Minh."Phân tích cú pháp và chuyển đổi ký tự sang âm vị (phoneme):
- Văn bản sau chuẩn hóa sẽ được phân tách thành từng đơn vị nhỏ hơn gọi là phoneme (đơn vị âm thanh nhỏ nhất).
Ví dụ minh họa:
Văn bản: "xin chào"
Phoneme tương ứng: "x i n - ch à o"Speech Generation (Sinh giọng nói)
Bước thứ hai này sẽ chuyển các phoneme sang âm thanh thực tế:
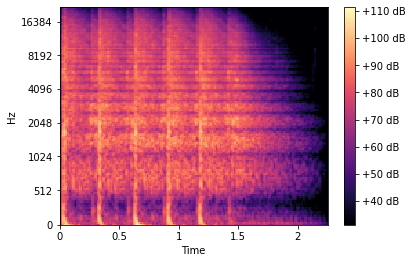
Tạo Mel-spectrogram:
- Mel-spectrogram là biểu đồ biểu diễn âm thanh theo thời gian (trục ngang) và tần số (trục dọc).
- Các phoneme được sử dụng để tạo ra các đặc trưng âm học phù hợp.
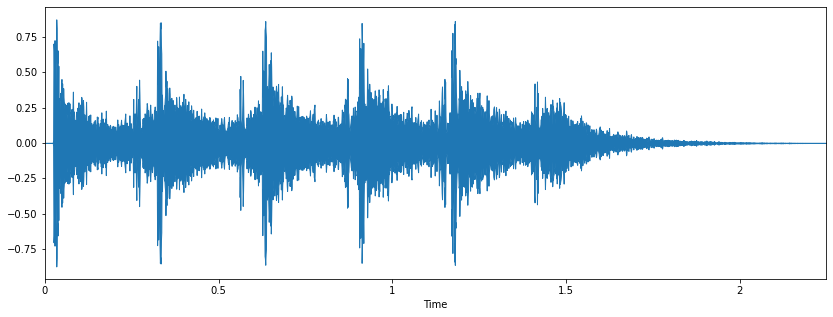
Tổng hợp dạng sóng âm thanh (Waveform synthesis):
- Mel-spectrogram sau đó được dùng làm đầu vào cho vocoder, là một mô hình chuyển đổi từ đặc trưng âm thanh sang sóng âm thanh nghe được.
- Ví dụ các vocoder phổ biến: WaveGlow, HiFi-GAN.
📊 Biểu đồ mô tả nguyên lý hoạt động TTS:
🛠️ Các kỹ thuật TTS thông dụng
- Concatenative synthesis (ghép các đoạn âm thanh sẵn có)
- Parametric synthesis (tổng hợp giọng nói dựa trên tham số)
- Deep Learning-based synthesis (Tacotron, FastSpeech, VITS…)
Trong những năm gần đây, kỹ thuật tổng hợp dựa trên Deep Learning phổ biến và đạt chất lượng âm thanh tự nhiên cao nhất.
Trên đây là những tóm tắt cơ bản về hệ thống TTS (Text-to-Speech) mà mình đã tìm hiểu trong thời gian qua. Ở những bài sắp tới mình sẽ tập trung vào các project nhỏ ví dụ cho các hệ thống TTS hiện đại sử dụng Deep Learning. Cảm ơn mọi người đã theo dõi